Huang Renxun’s Endorsement? SN3 Surges 5x in a Month, What Exactly Did It Do?
On March 20, 2026, an unusual conversation unfolded on the All-In venture capital podcast.
Venture capital heavyweight Chamath Palihapitiya turned to NVIDIA CEO Jensen Huang, mentioning that a project on Bittensor had “achieved a rather insane technical feat”: training a large language model on the internet using distributed computing power, a process that was completely decentralized with no centralized data centers involved.
Huang did not shy away. He likened it to “a modern version of Folding@home”, the distributed project from the 2000s that allowed ordinary users to contribute idle computing power to collectively tackle the protein folding problem.
Just four days earlier, on March 16, Anthropic co-founder Jack Clark, in a report on AI research progress, also dedicated significant space to highlight and reference this breakthrough: Bittensor ecosystem subnet Templar (SN3) had completed the distributed training of a 72-billion-parameter large model (Covenant 72B), with performance comparable to Meta’s LLaMA-2 released in 2023.
Jack Clark titled that section “Challenging AI Political Economy Through Distributed Training” and emphasized in his analysis that this is a technology worth continuous tracking—he could envision a future where on-device AI widely adopts models produced by decentralized training, while cloud AI continues to run proprietary large models.
The market’s reaction was slightly delayed but extremely intense: SN3 surged over 440% in the past month and over 340% in the past two weeks, reaching a market cap of $130 million. The narrative explosion of the subnet directly translates into buying pressure for TAO. Consequently, TAO rose rapidly, once reaching $377, doubling over the past month, with an FDV of approximately $7.5 billion.
The question arises: What exactly did SN3 do? Why was it thrust into the spotlight? And how will the value narrative of distributed training and decentralized AI evolve?
That 72B Model
To answer this, we must first examine the report card SN3 has submitted.
On March 10, 2026, the Covenant AI team published a technical report on arXiv, formally announcing the completion of Covenant-72B training. This is a 72-billion-parameter large language model, trained by over 70 independent node peers (with about 20 nodes synchronized per round, each equipped with 8 B200 GPUs), completing the pre-training of the 72B parameter model on a corpus of approximately 1.1 trillion tokens.

Templar provided some data on benchmark tests, comparing it to LLaMA-2-70B, a large model released by Meta in 2023. As Anthropic co-founder Jack Clark noted, Covenant-72B might be somewhat outdated by 2026 standards. Covenant-72B’s score of 67.1 on MMLU roughly corresponds to Meta’s LLaMA-2-70B (65.6) released in 2023.
Meanwhile, the cutting-edge models of 2026—whether GPT series, Claude, or Gemini—have long been trained on hundreds of thousands of GPUs with parameters far exceeding 100 billion. The gaps in reasoning, coding, and mathematical abilities are orders of magnitude, not percentage points. This reality gap should not be drowned out by market sentiment.
However, when framed within the premise of “trained using distributed computing power on the open internet,” the implications are entirely different.
For comparison: INTELLECT-1 (by Prime Intellect team, 10B parameters), another decentralized training project, scores 32.7 on MMLU; another distributed training project conducted among whitelisted participants, Psyche Consilience (40B parameters), scores 24.2. Covenant-72B, with its 72B scale and 67.1 MMLU score, is a standout figure in the decentralized training track.
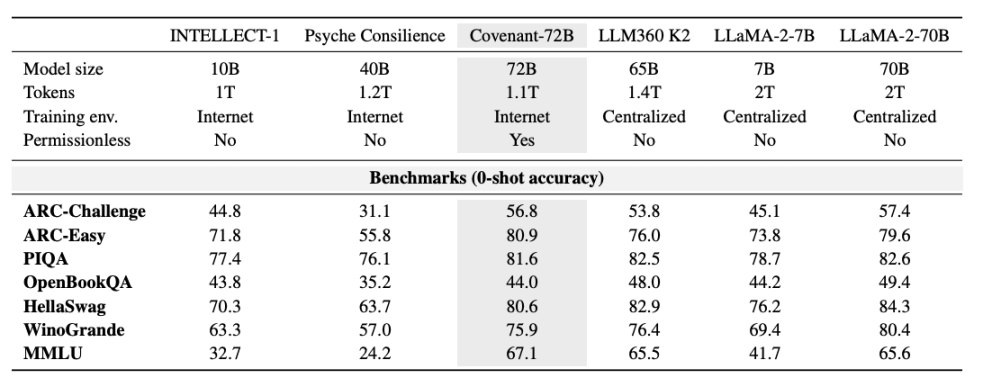
More crucially, this training was “permissionless.” Anyone could join as a participating node, no prior approval or whitelist required. Over 70 independent nodes participated in model updates, connecting from around the globe to contribute computing power.
What Jensen Huang Said, and What He Didn’t
Revisiting the details of that podcast conversation helps calibrate the external interpretation of this “endorsement.”
In the dialogue, Chamath Palihapitiya presented Bittensor’s technical achievement to Jensen Huang, describing it as training a Llama model with distributed computing power, a process that was “fully distributed while maintaining state.” Huang’s response was to compare it to a “modern version of Folding@home” and elaborated on the necessity for open-source and proprietary models to coexist in parallel.
It’s noteworthy that Huang did not directly mention Bittensor’s token or any investment implications, nor did he further discuss decentralized AI training.
Understanding Bittensor Subnets and SN3
To grasp SN3’s breakthrough, one must first understand Bittensor and its subnet operation logic. Simply put, Bittensor can be seen as an AI public chain and platform, where each subnet acts as an independent “AI production pipeline,” each with a clear core task and incentive mechanism design, working together to form a decentralized AI ecosystem.
Its operational process is clear and decentralized: subnet owners define subnet goals and code incentive models; miners provide computing power within subnets to complete AI-related tasks (like inference, training, storage, etc.); validators score the miners’ contributions and upload the scores to the Bittensor consensus layer; finally, Bittensor’s Yuma consensus algorithm allocates corresponding rewards to subnet participants based on the accumulated rewards of each subnet.
Currently, Bittensor has 128 subnets, covering various AI tasks such as inference, serverless AI cloud services, images, data labeling, reinforcement learning, storage, and computation.
SN3 is one such subnet. It doesn’t build application-layer wrappers or rent existing large model APIs. Instead, it directly targets one of the most expensive and closed core segments of the entire AI industry chain: large model pre-training itself.
SN3 aims to utilize the Bittensor network to coordinate distributed training across heterogeneous computing resources. Through incentivized distributed large model training, it seeks to prove that powerful foundational models can be trained without expensive centralized supercomputer clusters. The core appeal lies in “democratization”—breaking the resource monopoly of centralized training, allowing ordinary individuals or small-to-medium institutions to participate in large model training while leveraging distributed computing to reduce training costs.
The core force driving SN3’s development is Templar, with its research team being Covenant Labs. This team also operates two other subnets: Basilica (SN39, focused on compute services) and Grail (SN81, focused on RL post-training and model evaluation). These three subnets form a vertical integration, covering the entire process from pre-training to alignment optimization for large models, building a complete ecosystem for decentralized large model training.
Specifically, miners contribute computational resources, uploading gradient updates (the direction and magnitude of model parameter adjustments) to the network; validators assess the quality of each miner’s contribution, providing on-chain scores based on error improvement magnitude. The results determine reward weights, automatically allocated without needing to trust any third party.
The key to the incentive mechanism design is that rewards are directly tied to “how much your contribution improved the model,” not merely compute attendance. This fundamentally addresses the hardest problem in decentralized scenarios: how to prevent miners from slacking.
So how did Covenant-72B solve the communication efficiency and incentive compatibility problems?
Coordinating dozens of mutually distrusting nodes with varying hardware and network quality to train the same model presents two challenges: first, communication efficiency, as standard distributed training schemes require high-bandwidth, low-latency interconnections between nodes; second, incentive compatibility, how to prevent malicious nodes from submitting incorrect gradients? How to ensure each participant is genuinely training and not copying others’ results?
SN3 addresses these with two core components: SparseLoCo and Gauntlet.
SparseLoCo solves the communication efficiency problem. Traditional distributed training requires synchronizing full gradients at each step, involving massive data transfer. SparseLoCo’s approach: each node runs 30 steps of internal optimization (AdamW) locally, then compresses the resulting “pseudo-gradient” before uploading it to other nodes. Compression methods include Top-k sparsification (keeping only the most critical gradient components), error feedback (accumulating discarded parts for the next round), and 2-bit quantization. The final compression ratio exceeds 146x.
In other words, what originally required transmitting 100MB now needs less than 1MB.
This allows the system, under the bandwidth constraints of ordinary internet (110 Mbps upload, 500 Mbps download), to maintain computational utilization at about 94.5%—with 20 nodes, 8 B200s per node, and communication taking only 70 seconds per round.
Gauntlet solves the incentive compatibility problem. It runs on the Bittensor blockchain (Subnet 3), responsible for verifying the quality of pseudo-gradients submitted by each node. The specific method: using a small batch of data to test “how much the model loss decreased after applying this node’s gradient,” a result called LossScore. Simultaneously, the system checks if a node is training on its assigned data—if a node shows better loss improvement on random data than on its assigned data, it receives a negative score.
Ultimately, only the gradients from the highest-scoring nodes are selected for aggregation each training round, with the rest eliminated for that round. Excess participants are ready to fill in, keeping the system robust. Throughout the training, an average of 16.9 nodes’ gradients were included in aggregation per round, with over 70 unique node IDs having participated cumulatively.
The Value Narrative of Decentralized AI is Undergoing a Fundamental Shift
From a technical and industry perspective, the direction represented by Covenant-72B holds several real significances.
First, it breaks the presumption that “distributed training is only suitable for small models.” Although still far from cutting-edge models, it proves the scalability of this direction.
Second, permissionless participation is genuinely feasible. This point is underrated. Previous distributed training projects relied on whitelists—only vetted participants could contribute compute. In SN3’s training, anyone with sufficient computing power could join, with the verification mechanism filtering out malicious contributions. This is a concrete step towards “true decentralization.”
Third, Bittensor’s dTAO mechanism enables market discovery of subnet value. dTAO allows each subnet to issue its own Alpha token, using an AMM mechanism to let the market decide which subnets receive more TAO emissions. This provides a rough but effective value capture mechanism for subnets like SN3 that produce concrete results. Of course, this mechanism is also susceptible to narrative and sentiment interference, and the quality of LLM training outcomes is difficult for ordinary market participants to independently assess.
Fourth, the political-economic implications of decentralized AI training. Jack Clark elevated this issue in Import AI to the level of “who owns the future of AI.” Currently, cutting-edge model training is monopolized by a few institutions with massive data centers. This is not just a commercial issue but a power structure issue. If distributed training can sustain technological progress, it could potentially form a truly decentralized development ecosystem for certain model types (e.g., small-scale frontier models for specific domains). Of course, this prospect remains distant.
Summary: A Real Milestone, and a Pile of Real Problems
Jensen Huang said it’s like a “modern version of Folding@home.” Folding@home made real contributions in molecular simulation, but it didn’t threaten the core R&D positions of large pharmaceutical companies. This analogy is very accurate.
SN3 validated the protocol and proved a feasible direction for distributed training. But from a technical and industry perspective, behind this report card lies a pile of problems few are willing to seriously discuss:
MMLU itself is a controversial metric in academia, with risks of public benchmark questions and answers leaking into training datasets. More noteworthy is the selection of comparison baselines: the models compared in the paper, LLaMA-2-70B and LLM360 K2, are old models from 2023-2024. Scores in the 65-70 range are considered mid-to-low tier or entry-level when asking Grok or Doubao, and severely lagging in Claude’s view. Placing it on dynamically updated leaderboards or new-generation benchmarks with anti-contamination designs might yield more honest conclusions.
More critically, the high-quality data that determines a model’s capability ceiling—conversational data, code, mathematical derivations, scientific literature—is likely held by major corporations, publishing institutions, and academic databases. Computing power is democratized, but the data side remains an oligopoly. This contradiction hasn’t been discussed.
Regarding security, permissionless participation means you don’t know who is behind those 70+ nodes or what data they are training with. Gauntlet can filter out obviously anomalous gradients but cannot guard against subtle data poisoning—if a node systematically trains a few extra rounds in a direction of harmful content, the resulting gradient changes might be subtle enough to pass loss score screening but cause cumulative behavioral shifts in the model. The ultimate question: What risks does using a model trained by a handful of anonymous nodes with incomplete data provenance pose in high-compliance, high-security scenarios like finance, healthcare, or law?
There’s also a structural issue worth stating plainly: Covenant-72B itself is open-sourced under the Apache 2.0 license and does not use SN3 tokens. Holding SN3 tokens shares in the emission rewards from this subnet’s future continuous production of new models, not any direct revenue from the model’s usage. This value chain relies on continuous training output and the healthy operation of Bittensor’s overall network emission mechanism. If future training stalls or new training results fail to meet expectations, the token’s valuation logic weakens.
Listing these problems is not to negate the significance of Covenant-72B. It proved something previously thought impossible can be done, and that fact remains. But achieving it and what it means are two different things.
The SN3 token rose 440% in the past month. The gap here might not be mere speculation, but that narrative speed always outpaces reality. Whether this gap will be filled by reality or digested by market corrections depends on what the Covenant AI team truly delivers next.
It’s worth noting that Grayscale filed a TAO ETF application in January 2026, signaling institutional capital entering this track. Additionally, Bittensor halved its daily TAO emissions in December 2025, and the structural tightening on the supply side is still unfolding.
Reference Links:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95
यह लेख इंटरनेट से लिया गया है: Huang Renxun’s Endorsement? SN3 Surges 5x in a Month, What Exactly Did It Do?
Related: AI is Paying Humans to Do That
Author | Dingdang(@XiaMiPP) Yesterday, we might have been debating whether AI will replace humans; today, the question might be shifting to whether AI will start managing humans. After OpenClaw ignited the AI Agent frenzy, industry attention has largely focused on the “capability demonstrations” of Agents: they can manage emails and schedules, automate tasks, browse the web, run scripts, acting like digital butlers that never clock out. However, this remains a familiar imagination: humans set the goals, and AI is responsible for execution. But their evolution is incredibly fast. They have already begun to possess their own social networks, autonomously communicate, self-organize, and even developed their own subcultures and nascent religions. Related reading: “From Moltbook to MOLT: How is the Imagination of AI Autonomy Being Embraced by the Crypto बाज़ार?” And…







