Gate Ventures Research Insights: The Third Browser War, the Entry Battle in the AI Agent Era
TL;DR
The third browser war is quietly unfolding. Looking back at history, from Netscape and Microsofts IE in the 1990s to the open-source Firefox and Googles Chrome, the browser war has always been a concentrated reflection of platform control and technological paradigm shifts. Chrome has won the dominant position by virtue of its update speed and ecological linkage, while Google has formed a closed loop of information entry through the duopoly structure of search and browser.
But today, this pattern is being shaken. The rise of large language models (LLMs) has enabled more and more users to complete tasks on search results pages with zero clicks, and traditional web page clicks are decreasing. At the same time, rumors that Apple intends to replace the default search engine in Safari further threaten the profit foundation of Alphabet (Googles parent company), and the market has begun to show uneasiness about search orthodoxy.
The browser itself is also facing a role reshaping. It is not only a tool for displaying web pages, but also a collection of multiple capabilities such as data input, user behavior, and privacy identity. Although AI Agent is powerful, it still needs to rely on the browsers trust boundary and function sandbox to complete complex page interactions, call local identity data, and control web page elements. The browser is changing from a human interface to an agents system call platform.
In this article, we explore whether browsers are still necessary. At the same time, we believe that what is likely to break the current browser market is not another better Chrome, but a new interaction structure: not the display of information, but the calling of tasks. In the future, browsers should be designed for AI agents – not only reading, but also writing and executing. Projects like Browser Use are trying to semanticize the page structure, turning the visual interface into structured text that can be called by LLM, realizing the mapping of pages to instructions, and greatly reducing the interaction cost.
Mainstream projects on the market have begun to test the waters: Perplexity built a native browser Comet, using AI to replace traditional search results; Brave combined privacy protection with local reasoning, using LLM to enhance search and blocking functions; and Crypto native projects such as Donut are targeting new entry points for AI to interact with on-chain assets. The common feature of these projects is that they try to reconstruct the input end of the browser rather than beautify its output layer.
For entrepreneurs, opportunities are hidden in the triangle relationship between input, structure and agent. As the interface for agents to call the world in the future, browsers mean that whoever can provide structured, callable and trustworthy capability blocks can become a part of the new generation of platforms. From SEO to AEO (Agent Engine Optimization), from page traffic to task chain calls, product forms and design thinking are being reconstructed. The third browser war took place in input rather than display; the winner is no longer determined by who catches the users eye, but who wins the trust of the agent and obtains the entry point for calling.
A brief history of browser development
In the early 1990s, when the Internet had not yet become a part of daily life, Netscape Navigator was born, like a sailing ship that opened up a new continent, opening the door to the digital world for millions of users. This browser was not the first, but it was the first product that truly went to the masses and shaped the Internet experience. At that time, for the first time, people could browse the web so easily through a graphical interface, as if the whole world suddenly became within reach.
However, glory is often short-lived. Microsoft soon realized the importance of browsers and decided to forcefully bundle Internet Explorer into the Windows operating system, making it the default browser. This strategy can be called a platform killer and directly undermined Netscapes market dominance. Many users did not actively choose IE, but accepted it because the system accepted it by default. With the help of Windows distribution capabilities, IE quickly became the industry leader, and Netscape fell into a track of decline.

Firefox Logo Evolution
In the difficult situation, Netscape engineers chose a radical and idealistic path – they made the browser source code public and called on the open source community. This decision seemed to be a Macedonian concession in the technology world, heralding the end of the old era and the rise of new forces. This code later became the basis of the Mozilla browser project, which was originally named Phoenix (meaning phoenix nirvana), but was renamed several times due to trademark issues and was finally named Firefox.
Firefox is not a simple copy of Netscape. It has achieved many breakthroughs in user experience, plug-in ecology, security, etc. Its birth marks the victory of the open source spirit and injects new vitality into the entire industry. Some people describe Firefox as the spiritual successor of Netscape, just as the Ottoman Empire inherited the afterglow of Byzantium. Although this metaphor is exaggerated, it is quite meaningful.
But a few years before Firefox was officially released, Microsoft had already released six versions of IE. Relying on the time advantage and system bundling strategy, Firefox was in a catching-up position from the beginning, which meant that this competition was not a fair competition with equal starting points.
At the same time, another early player was quietly making its debut. In 1994, the Opera browser came out from Norway and was initially just an experimental project. But starting with version 7.0 in 2003, it introduced its own Presto engine, and was the first to support cutting-edge technologies such as CSS, adaptive layout, voice control, and Unicode encoding. Although the number of users was limited, it was always at the forefront of the industry in terms of technology, becoming a geek favorite.
In the same year, Apple launched the Safari browser. This was a significant turn of events. At that time, Microsoft had invested $150 million in Apple, which was on the verge of bankruptcy, to maintain the appearance of competition and avoid antitrust scrutiny. Although Safaris default search engine has been Google since its birth, this historical entanglement with Microsoft symbolizes the complex and delicate relationship between Internet giants: cooperation and competition always go hand in hand.
In 2007, IE 7 was launched with Windows Vista, but the market response was mediocre. On the other hand, Firefox, with its faster update rhythm, more friendly extension mechanism and natural appeal to developers, has steadily increased its market share to about 20%. IEs dominance is gradually loosening, and the wind direction is changing.
Google has a different approach. Although it has been planning to build its own browser since 2001, it took six years to convince CEO Eric Schmidt to approve the project. Chrome was launched in 2008, based on the Chromium open source project and the WebKit engine used by Safari. It was nicknamed a bloated browser, but it quickly rose to prominence thanks to Googles deep expertise in advertising and branding.
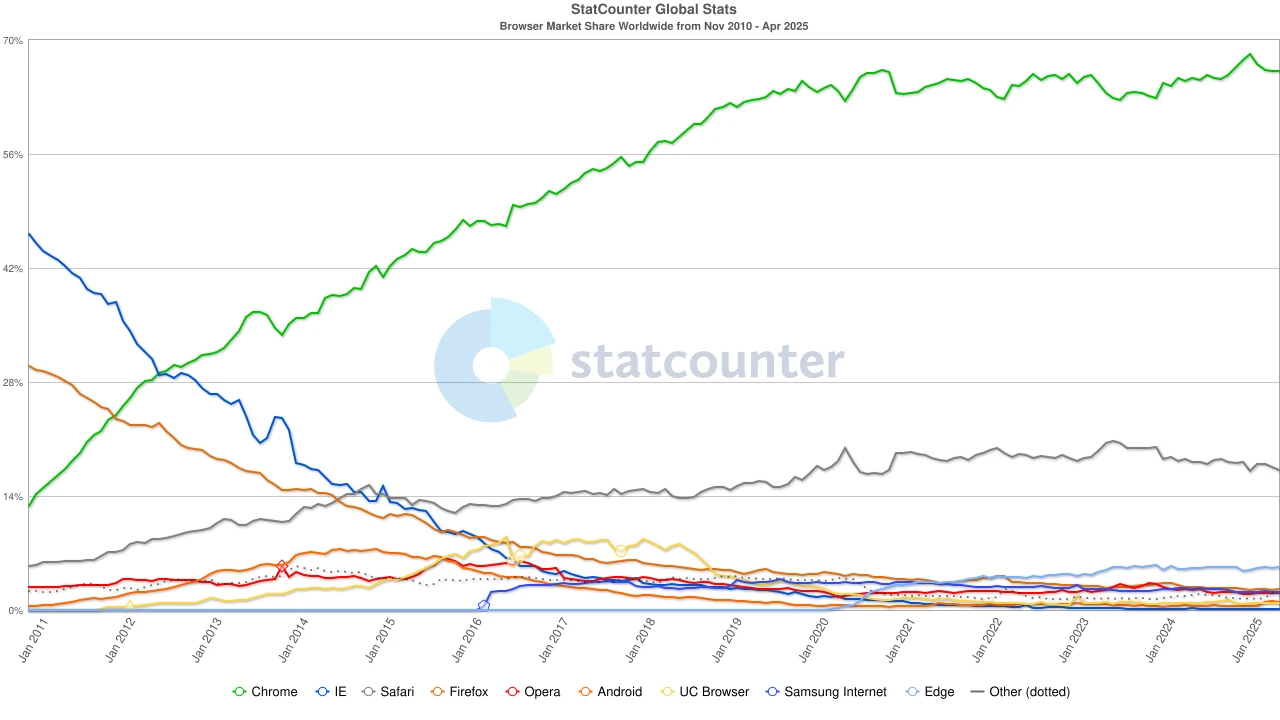
Chromes key weapon is not its features, but its frequent version updates (once every six weeks) and unified experience across all platforms. In November 2011, Chrome surpassed Firefox for the first time, reaching a market share of 27%; six months later, it surpassed IE, completing the transformation from a challenger to a dominant player.
At the same time, Chinas mobile Internet is also forming its own ecosystem. Alibabas UC Browser quickly became popular in the early 2010s, especially in emerging markets such as India, Indonesia, and China. It won the favor of low-end device users with its lightweight design, data compression and traffic saving features. In 2015, its global mobile browser market share exceeded 17%, and once reached 46% in India. But this victory was not lasting. As the Indian government strengthened its security review of Chinese applications, UC Browser was forced to withdraw from key markets and gradually lost its former glory.
Browser market share, source: statcounter
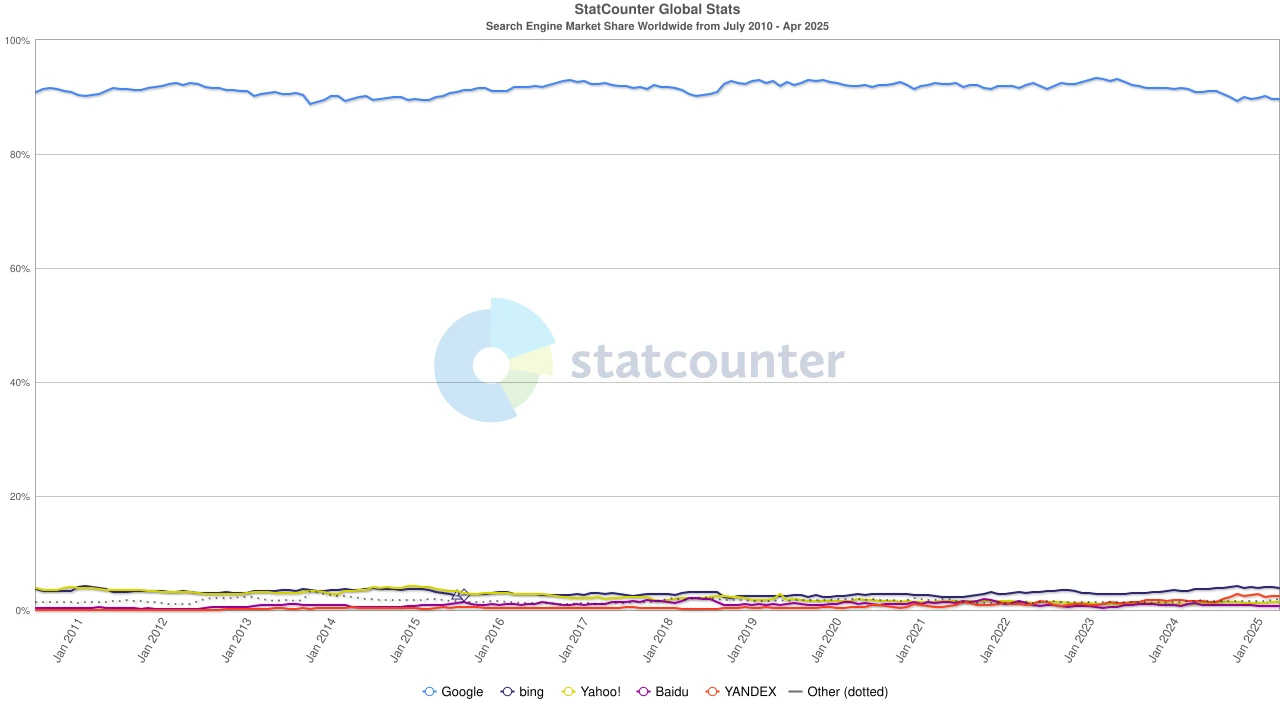
Entering the 2020s, Chromes dominance has been established, with a global market share of about 65%. It is worth noting that although the Google search engine and the Chrome browser belong to Alphabet, they are two independent hegemonic systems from a market perspective – the former controls about 90% of the worlds search portals, while the latter controls the first window for most users to enter the Internet.
In order to maintain this dual monopoly structure, Google has invested heavily. In 2022, Alphabet paid Apple about $20 billion just to keep Google as the default search in Safari. Some analysts pointed out that this expenditure is equivalent to 36% of Googles search advertising revenue from Safari traffic. In other words, Google is paying protection fees for its moat.
Search Engine market share, source: statcounter
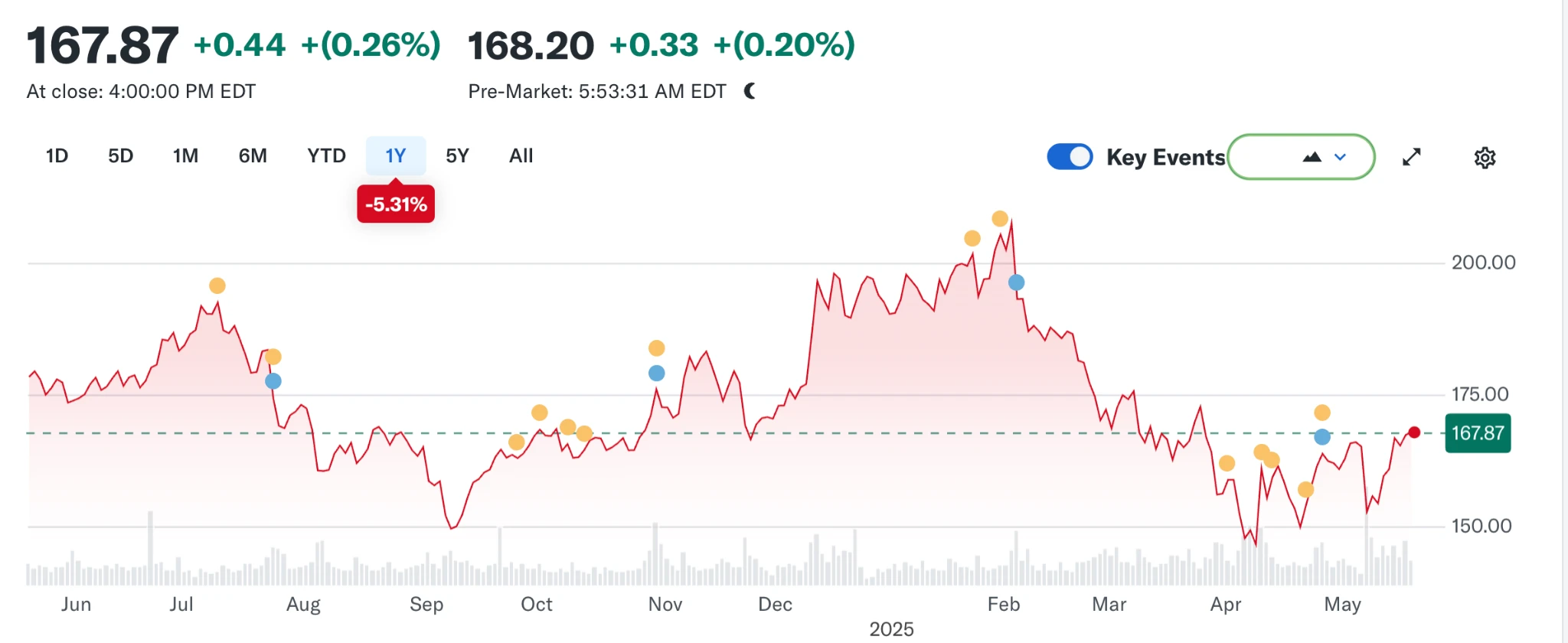
But the wind direction has changed again. With the rise of large language models (LLMs), traditional search has begun to be impacted. In 2024, Googles search market share fell from 93% to 89%. Although it still dominates, cracks are beginning to appear. Even more subversive is the rumor that Apple may launch its own AI search engine. If Safaris default search switches to its own camp, this will not only rewrite the ecological landscape, but may also shake Alphabets profit pillar. The market reacted quickly, and Alphabets stock price fell from $170 to $140, reflecting not only investors panic, but also deep uneasiness about the future direction of the search era.
From Navigator to Chrome, from open source ideals to advertising commercialization, from lightweight browsers to AI search assistants, the browser war has always been a war about technology, platform, content and control. The battlefield keeps shifting, but the essence has never changed: whoever controls the entrance defines the future.
In the eyes of VCs, relying on the new demands of people on search engines in the LLM and AI era, the third browser war is gradually unfolding. The following is the financing status of some well-known AI browser projects.


The old architecture of modern browsers
When it comes to the architecture of browsers, the classic traditional architecture is shown in the figure below:
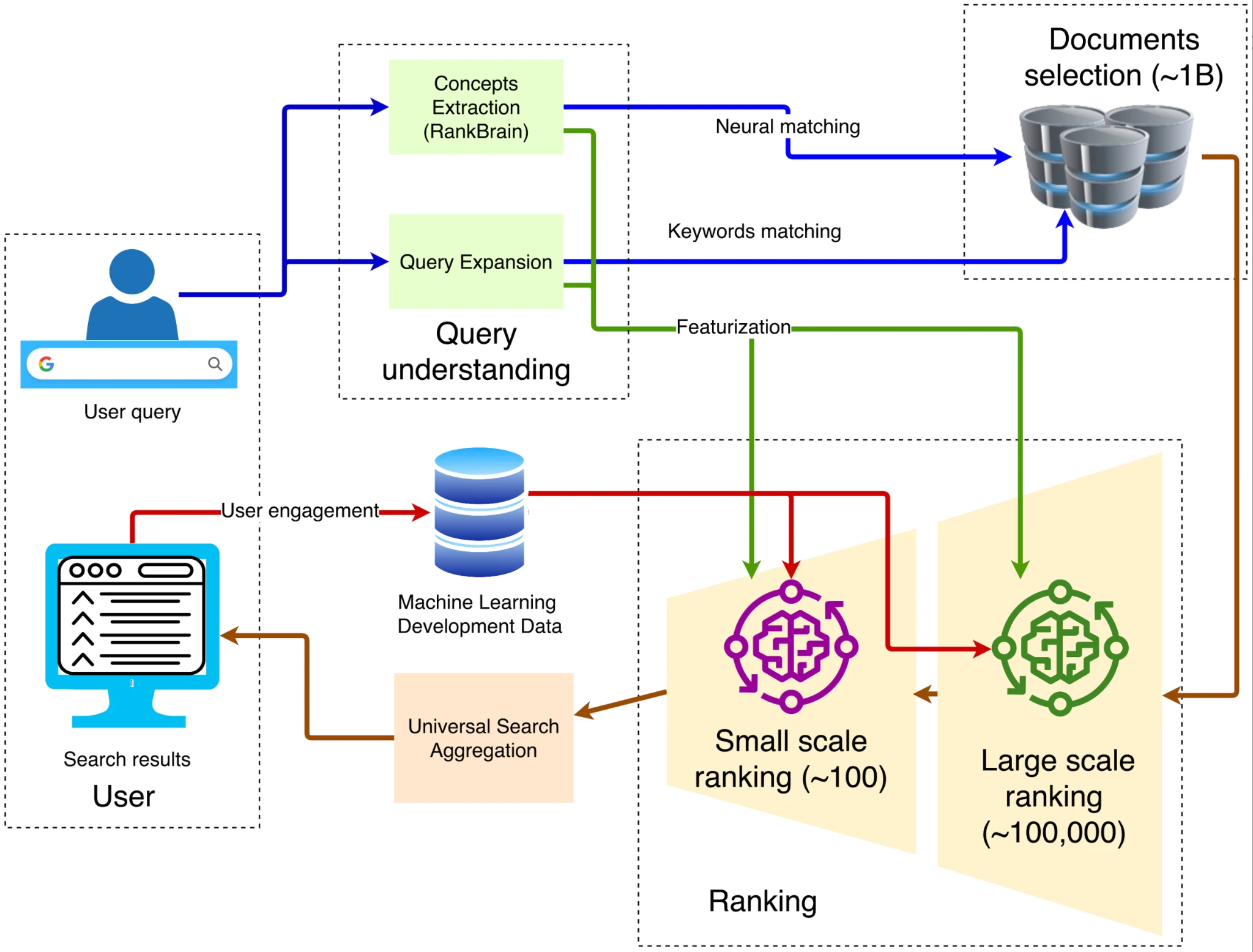
The overall architecture, source: Damien Benveniste
1. Client-frontend entry
The query is sent to the nearest Google Front End via HTTPS, completing TLS decryption, QoS sampling, and geographic routing. If abnormal traffic (DDoS, automatic crawling) is detected, it can be limited or challenged at this layer.
2. Query Understanding
The front end needs to understand the meaning of the words typed by the user, which involves three steps: neural spelling correction, which corrects recpie to recipe; synonym expansion, which expands how to fix bike to repair bicycle; and intent analysis, which determines whether the query is for information, navigation, or transactional intent, and assigns Vertical requests.
3. Candidate recall

Inverted Index, source: spot intelligence
The query technology used by Google is called: inverted index. In the forward index, we can index the file given an ID. However, it is impossible for users to know the number of the desired content in hundreds of billions of files, so it uses a very traditional inverted index to query which files have corresponding keywords through content. Next, Google uses vector indexing to process semantic search, that is, to find content with similar meaning to the query. It converts text, images and other content into high-dimensional vectors (embedding) and searches based on the similarity between these vectors. For example, even if a user searches for how to make pizza dough, the search engine can return results related to pizza dough making 指导 because they are semantically similar. After the inverted index and vector index, about 100,000 web pages will be initially screened out.
4. Multi-level sorting
The system usually uses thousands of light features such as BM2 5, TF-IDF, and page quality score to filter candidate pages from hundreds of thousands to about 1,000 pages to form a preliminary candidate set. Such systems are collectively referred to as recommendation engines. They rely on massive features generated by multiple entities, including user behavior, page attributes, query intent, and contextual signals. For example, Google will integrate information such as user history, behavioral feedback from other users, page semantics, query meaning, etc., while also considering contextual factors such as time (time of day, specific day of the week) and external events such as real-time news.
5. Deep learning for primary sorting
In the initial retrieval stage, Google uses technologies such as RankBrain and Neural Matching to understand the semantics of the query and filter out preliminary relevant results from a large number of documents. RankBrain is a machine learning system introduced by Google in 2015, designed to better understand the meaning of user queries, especially those that appear for the first time. It finds the most relevant results by converting queries and documents into vector representations and calculating the similarity between them. For example, for the query how to make pizza dough, RankBrain can identify content related to pizza basics or dough making even if there are no exact matching keywords in the document.
Neural Matching is another technology that Google launched in 2018 to gain a deeper understanding of the semantic relationship between queries and documents. It uses a neural network model to capture the fuzzy relationships between words, helping Google better match queries and web page content. For example, for the query Why is my laptop fan so loud?, Neural Matching can understand that the user may be looking for troubleshooting information about overheating, dust accumulation, or high CPU usage, even if these words do not appear directly in the query.
6. Deep Reranking: Application of BERT Model
After initially screening out relevant documents, Google uses the BERT (Bidirectional Encoder Representations from Transformers) model to sort these documents more finely to ensure that the most relevant results are ranked first. BERT is a pre-trained language model based on Transformer that can understand the contextual relationship between words in a sentence. In search, BERT is used to re-rank the documents that are initially retrieved. It re-ranks documents by jointly encoding the query and the document and calculating the relevance score between them. For example, for the query parking on a ramp without a curb, BERT can understand the meaning of no curb and return a page that recommends that the driver turn the wheel toward the curb, rather than misinterpreting it as a situation with a curb. For SEO engineers, it is necessary to accurately learn the recommendation algorithms of Google ranking and machine learning to optimize the content of web pages in a targeted manner to obtain a higher ranking display.
The above is a typical workflow of Google search engine. However, in the current era of AI and big data explosion, users have new demands for browser interaction.
Why AI will reshape the browser
First of all, we need to clarify why the browser form still exists? Is there a third form, an option other than artificial intelligence agents and browsers?
We believe that existence is irreplaceable. Why can artificial intelligence use browsers but cannot completely replace them? Because browsers are universal platforms, not only an entry point for reading data, but also a universal entry point for inputting data. This world cannot only have information input, but also must generate data and interact with websites, so browsers that integrate personalized user information will still exist widely.
We grasp this point: the browser is a universal entry point, not only for reading data, but users often need to interact with the data. The browser itself is an excellent place to store user fingerprints. More complex user behaviors and automated behaviors must be carried out through the browser. The browser can store all user behavior fingerprints, passes and other privacy information, and implement trustless calls during the automation process. The actions of interacting with data can evolve into:
User → Invoke AI Agent → Browser.
In other words, the only part that may be replaced is the part that is in line with the worlds evolutionary trend – more intelligent, more personalized, and more automated. Admittedly, this part can be handled by AI Agent, but AI Agent itself is by no means a suitable place to carry user personalized content, because it faces multiple challenges in terms of data security and convenience. Specifically:
The browser is where personalized content is stored:
1. Most large models are hosted in the cloud, and the session context is saved on the server, making it difficult to directly call sensitive data such as local passwords, wallets, and cookies.
2. Sending all browsing and payment data to a third-party model requires re-authorization from the user; both the EU DMA and US state privacy laws require minimizing data outbound transfer.
3. Automatically filling in the two-factor verification code, calling the camera, or using the GPU for WebGPU inference must all be done in the browser sandbox.
4. The data context is highly dependent on the browser, including tabs, cookies, IndexedDB, Service Worker Cache, Passkey credentials, and extended data, all of which are deposited in the browser.
A profound change in the form of interaction
Back to the topic at the beginning, our behavior of using browsers can be roughly divided into three forms: reading data, inputting data, and interacting with data. The artificial intelligence big model (LLM) has profoundly changed the efficiency and way of reading data. In the past, users behavior of searching web pages based on keywords seemed very old and inefficient.
There have been many studies analyzing the evolution of user search behavior – whether to obtain summarized answers or click on web pages.
In terms of user behavior patterns, a 2024 study showed that in every 1,000 Google queries in the United States, only 374 ended up clicking on an open web page. In other words, nearly 63% were zero-click behaviors. Users are accustomed to getting information such as weather, exchange rates, and knowledge cards directly from the search results page.
In terms of user psychology, a 2023 survey pointed out that 44% of respondents believed that regular natural results were more trustworthy than featured snippets. Academic research has also found that in controversial topics or where there is no unified truth, users prefer result pages that contain multiple source links.
That is to say, some users do not trust AI summaries very much, but a considerable proportion of user behavior has shifted to zero click. Therefore, AI browsers still need to explore an appropriate interactive form – especially in the data reading part, because the hallucination problem of the current large model has not been eradicated, and many users still find it difficult to fully trust the automatically generated content summary. In this regard, if the large model is embedded in the browser, there is actually no need to make a disruptive change to the browser, but only to gradually solve the accuracy and controllability of the model. This improvement is also being continuously promoted.
What may really trigger a large-scale change in browsers is the data interaction layer. In the past, people completed interactions by entering keywords – this was the limit of what the browser could understand. Now, users are increasingly inclined to use a whole paragraph of natural language to describe complex tasks, such as:
● “Find direct flights from New York to Los Angeles for a certain time period”
● “Looking for flights from New York to Shanghai and then to Los Angeles”
These behaviors, even for humans, require a lot of time to visit multiple websites, collect and compare data. However, these agentic tasks are gradually being taken over by AI agents.
This is also in line with the direction of historical evolution: automation and intelligence. People are eager to free their hands, and AI Agents will be deeply embedded in browsers. Future browsers must be designed for full automation, especially considering:
● How to balance the human reading experience and the AI Agent’s parsability,
● How to serve both users and agent models on the same page.
Only when the design meets these two requirements can the browser truly become a stable carrier for AI Agent to perform tasks.
Next, we will focus on five highly anticipated projects, including Browser Use, Arc (The Browser Company), Perplexity, Brave, and Donut. These projects represent the future evolution of AI browsers and their potential for native integration in Web3 and Crypto scenarios.
Browser Use
This is the core logic behind the huge financing of Perplexity and Browser Use. In particular, Browser Use is the second most certain and growth potential innovation opportunity emerging in the first half of 2025.

Browser Use, source: Browser Use
The browser has built a true semantic layer, the core of which is to build a semantic recognition architecture for the next generation of browsers.
Browser Use decodes the traditional DOM = node tree for humans into semantic DOM = instruction tree for LLM, allowing agents to accurately click, fill in and upload without looking at the coordinates of the film points; this route replaces visual OCR or coordinate Selenium with structured text → function call, so the execution is faster, tokens are saved, and there are fewer errors. TechCrunch calls it the glue layer that allows AI to truly understand web pages, and the $17 million seed round completed in March is a bet on this underlying innovation.
After HTML rendering, a standard DOM tree is formed; the browser then derives an accessibility tree to provide screen readers with richer role and state labels.
1. Abstract each interactive element (
2. Translate the entire page into a flattened semantic node list for LLM to read at once in the system prompt;
3. Receive high-level instructions (such as click(node_id=btn-Checkout)) output by LLM and play them back to the real browser. The official blog calls this process converting the website interface into structured text that can be parsed by LLM.
At the same time, once this set of standards is introduced into W3C, it can largely solve the problem of browser input. We use The Browser Companys open letter and case to further explain why The Browser Companys idea is wrong.
Arc
The Browser Company (Arcs parent company) stated in its open letter that the ARC browser will enter the regular maintenance phase, and the team will focus on DIA, a browser that is completely oriented to AI. The letter also admitted that the specific implementation path of DIA has not yet been determined. At the same time, the team made several predictions about the future browser market in the letter. Based on these predictions, we further believe that if we want to truly subvert the existing browser landscape, the key lies in changing the output on the interactive side.
Here are three predictions weve captured from the ARC team about the future of the browser market.
Webpages wont be the primary interface anymore. Traditional browsers were built to load webpages. But increasingly, webpages — apps, articles, and files — will become tool calls with AI chat interfaces. In many ways, chat interfaces are already acting like browsers: they search, read, generate, respond. They interact with APIs, LLMs, databases. And people are spending hours a day in them. If youre skeptical, call a cousin in high school or college — natural language interfaces, which abstract away the tedium of old computing paradigms, are here to stay.
But the Web isnt going anywhere — at least not anytime soon. Figma and The New York Times arent becoming less important. Your boss isnt ditching your teams SaaS tools. Quite the opposite. Well still need to edit documents, watch videos, read weekend articles from our favorite publishers. Said more directly: webpages wont be replaced — theyll remain essential. Our tabs arent expendable, they are our core context. That is why we think the most powerful interface to AI on desktop wont be a web browser or an AI chat interface — itll be both. Like peanut butter and jelly. Just as the iPhone combined old categories into something radically new, so too will AI browsers. Even if its not ours that wins.
New interfaces start from familiar ones. In this new world, two opposing forces are simultaneously true. How we all use computers is changing much faster (due to AI) than most people acknowledge. Yet at the same time, were much farther from completely abandoning our old ways than AI insiders give credit for. Cursor proved this thesis in the coding space: the breakthrough AI app of the past year was an (old) IDE — designed to be AI-native. OpenAI confirmed this theory when they bought Windsurf (another AI IDE), despite having Codex working quietly in the background. We believe AI browsers are next.
First, it believes that webpages are no longer the main interactive interface. Admittedly, this is a challenging judgment, and it is also the key reason why we have reservations about the results of its founders reflection. In our opinion, this view significantly underestimates the role of browsers, which is also the key issue that it ignores when exploring the path of AI browsers.
Big models excel at capturing intent, such as understanding commands like “book me a flight.” However, they still fall short in terms of information density. When users need a dashboard, a Bloomberg Terminal-style notepad, or a visual canvas like Figma, nothing beats a dedicated web page arranged with pixel-perfect precision. The ergonomic design tailored to each product—charts, drag-and-drop functions, hotkeys—is not decorative dross, but rather compressed cognitive affordances. These capabilities cannot be carried by simple conversational interactions. Taking Gate.com as an example, if users want to make investment operations, relying solely on AI dialogue is far from enough because users have a high dependence on information input, accuracy, and structured presentation.
The RC team has an essential deviation in its path assumption, that is, it fails to clearly distinguish that interaction consists of two dimensions: input and output. On the input side, its view is reasonable in some scenarios, and AI can indeed improve the efficiency of command-based interaction; but on the output side, the judgment is obviously unbalanced, ignoring the core role of the browser in information presentation and personalized experience. For example, Reddit has its unique layout and information architecture, while AAVE has a completely different interface and structure. As a platform that can accommodate highly private data and render a variety of product interfaces, the browsers substitutability at the input layer is limited, and on the output side, its complexity and non-standardization make it difficult to be subverted. In contrast, the current AI browsers on the market are more focused on the output summary level: summarizing web pages, refining information, and generating conclusions, which are not enough to constitute a fundamental challenge to mainstream browsers or search systems such as Google, and only the market share of search summaries is divided.
Therefore, the one who can really shake up Chrome, which has a market share of up to 66%, is destined not to be the next Chrome. To achieve this disruption, the browsers rendering mode must be fundamentally reshaped so that it can adapt to the interactive needs dominated by AI Agents in the intelligent era, especially in the architectural design of the input side. For this reason, we are more in favor of the technical path taken by Browser Use – its focus is on the structural changes in the underlying mechanisms of the browser. Once any system is atomized or modularized, the resulting programmability and combinability will bring extremely destructive disruptive potential, and this is exactly the direction Browser Use is currently advancing.
In summary, the operation of AI Agent is still highly dependent on the existence of the browser. The browser is not only the main storage place for complex personalized data, but also the universal rendering interface for diversified applications, so it will continue to serve as the core interaction entrance in the future. As AI Agent is deeply embedded in the browser to complete fixed tasks, it will interact with specific applications by calling user data, that is, it mainly acts on the input side. To this end, the existing rendering mode of the browser needs to be innovated to achieve maximum compatibility and adaptation with AI Agent, so as to capture applications more effectively.
Perplexity
Perplexity is an AI search engine known for its recommendation system. Its latest valuation is as high as $14 billion, nearly five times the $3 billion in June 2024. It processes more than 400 million search queries per month, and processed about 250 million queries in September 2024. The number of user queries increased eightfold year-on-year, and the number of monthly active users exceeded 30 million.
Its main feature is that it can summarize pages in real time, which gives it an advantage in obtaining instant information. Earlier this year, it began to build its own native browser, Comet. Perplexity describes the upcoming Comet as a browser that not only displays web pages, but also thinks about them. Officials said it will deeply embed Perplexitys answer engine inside the browser, which is a Steve Jobs-style whole machine idea: burying AI tasks deep into the bottom layer of the browser, rather than making sidebar plug-ins. Replace the traditional ten blue links with concise answers with citations, competing directly with Chrome.

Google I/O 2025
But it still needs to solve two core problems: high search costs and low profit margins from marginal users. Although Perplexity is already in a leading position in the field of AI search, Google also announced a large-scale intelligent reshaping of its core products at the 2025 I/O conference. In response to the reshaping of the browser, Google launched a new browser tab experience called AI Model, which integrates Overview, Deep Research and future Agentic features. The overall project is called Project Mariner.
Google is actively reshaping AI, so it is difficult to pose a real threat to it by merely imitating its functions on the surface, such as Overview, DeepResearch or Agentics. What is really likely to establish a new order in chaos is to reconstruct the browser architecture from the bottom up, deeply embed the large language model (LLM) into the browser kernel, and achieve a fundamental change in the way of interaction.
勇敢的
Brave is the earliest and most successful browser in the Crypto industry. It is based on the Chromium architecture and is therefore compatible with plug-ins on the Google Store. It relies on privacy and the model of earning tokens through browsing to attract users. Braves development path has demonstrated its growth potential to a certain extent. However, from a product perspective, privacy is important, but its demand is still mainly concentrated in specific user groups, and privacy awareness has not yet become a mainstream decision-making factor for the general public. Therefore, the possibility of trying to subvert existing giants by relying on this feature is low.
As of now, Brave has 82.7 million monthly active users and 35.6 million daily active users, with a market share of about 1% – 1.5%. The user scale continues to grow: from 6 million in July 2019 to 25 million in January 2021, 57 million in January 2023, and more than 82 million in February 2025, with an average annual compound growth rate of double digits. Its average monthly search query volume is about 1.34 billion times, which is about 0.3% of Google.
Here is Brave’s iterative roadmap.
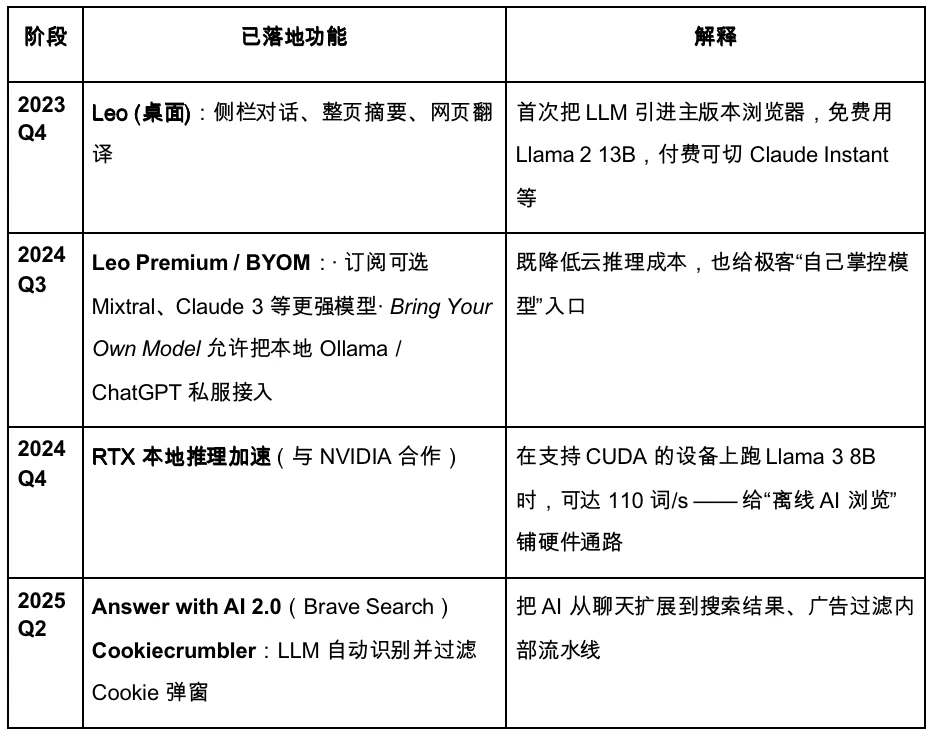
Brave is planning to upgrade to a privacy-first AI browser. However, due to the limited access to user data, the large model is less customizable, which is not conducive to fast and accurate product iteration. In the upcoming Agentic Browser era, Brave may maintain a stable share among certain privacy-conscious user groups, but it is difficult to become a major player. Its AI assistant Leo is more like a plug-in, which only enhances the functionality of existing products and has a certain ability to summarize content, but there is no clear strategy to fully switch to AI Agent, and innovation at the interaction level is still insufficient.
Donut
Recently, the Crypto industry has also made progress in the field of Agentic Browser. The startup project Donut received $7 million in financing in the Pre-seed round, led by Sequoia China (Hongshan), HackVC and Bitkraft Ventures. The project is still in the early conceptual stage, and the vision is to achieve the integrated capabilities of discovery, decision-making, and crypto-native execution.
The core of this direction is to combine the encryption-native automated execution path. As a16z predicted, in the future, Agent is expected to replace search engines as the main traffic entrance. Entrepreneurs will no longer compete around Googles ranking algorithm, but compete for the access and conversion traffic brought by Agent execution. The industry has called this trend AEO (Answer/Agent Engine Optimization), or further ATF (Agentic Task Fulfilment), that is, no longer optimizing search rankings, but directly serving intelligent models that can complete tasks such as placing orders, booking tickets, and writing letters for users.
For entrepreneurs
First of all, we must admit that the browser itself is still the largest entry point in the Internet world that has not been reconstructed. There are about 2.1 billion desktop users and over 4.3 billion mobile users worldwide. It is a common carrier for data input, interactive behavior, and personalized fingerprint storage. The reason why this form persists is not because of inertia, but because the browser naturally has a two-way attribute: it is both a reading entry for data and a writing exit for behavior.
Therefore, for entrepreneurs, the real disruptive potential is not the optimization at the page output level. Even if you can implement an AI overview function similar to Google in a new tab, it is essentially an iteration of the browser plug-in layer and has not yet constituted a fundamental paradigm change. The real breakthrough lies in the input side – that is, how to make the AI Agent actively call the entrepreneurs product to complete specific tasks. This will become the key to whether future products can be embedded in the Agent ecosystem and obtain traffic and value distribution.
In the search era, it’s called “click”; in the agency era, it’s called “call”.
If you are an entrepreneur, you might as well reimagine your product as an API component—so that the intelligent agent can not only read it, but also call it. This requires you to consider three dimensions at the beginning of product design:
1. Standardization of interface structure: Is your product “callable”?
Whether a product has the ability to be called by an intelligent agent depends on whether its information structure can be standardized and abstracted into a clear schema. For example, can key operations such as user registration, order buttons, and comment submission be described through semantic DOM structures or JSON mappings? Does the system provide a state machine so that the agent can stably reproduce the user behavior process? Does the users interaction on the page support scripted restoration? Is there a stable access WebHook or API Endpoint?
This is the essential reason for the successful financing of Browser Use – it transforms the browser from flat-rendered HTML to a semantic tree that can be called by LLM. For entrepreneurs, introducing similar design concepts in web products is to make structural adaptations for the AI Agent era.
2. Identity and Access: Can you help the Agent “cross the trust barrier”?
For AI agents to complete transactions, call payments or assets, they need some kind of trusted middle layer – can you be it? Browsers can naturally read local storage, call wallets, identify verification codes, and access two-factor authentication, which is why they are more suitable for execution than large cloud models. This is especially true in Web3 scenarios: the interface standards for calling on-chain assets are not unified, and agents will be unable to move forward without identity or signature capabilities.
Therefore, for Crypto entrepreneurs, there is an imaginative blank area: MCP (Multi Capability Platform) in the blockchain world. This can be a general instruction layer (letting Agent call Dapp), a standardized contract interface set, or even a lightweight wallet + identity middle platform running locally.
3. Re-understanding of traffic mechanism: The future is not SEO, but AEO/ATF
In the past, you had to win the favor of Googles algorithm; now you have to be embedded in the task chain by AI Agent. This means that the product must have clear task granularity: not a page, but a string of callable capability units; it means that you have to start doing Agent Optimization (AEO) or Task Scheduling Adaptation (ATF): for example, whether the registration process can be simplified into structured steps, whether pricing can be pulled through the interface, and whether inventory can be checked in real time;
You even need to start adapting the calling syntax under different LLM frameworks – OpenAI and Claude have different preferences for function calls and tool usage. Chrome is the terminal to the old world, not the entrance to the new world. The real entrepreneurial project with a future is not to create a new browser, but to make the existing browser serve the Agent and build a bridge for the new generation of instruction flow.
What you need to build is the interface syntax for the Agent to call your world;
What you are striving for is to become a link in the trust chain of the intelligent entity;
What you need to build is the API Castle in the next search mode.
If Web2 relies on UI to grab the users attention, then in the Web3 + AI Agent era, it relies on the call chain to grasp the agents execution intention.
免责声明:
This content does not constitute any offer, solicitation, or recommendation. You should always seek independent professional advice before making any investment decision. Please note that Gate and/or Gate Ventures may restrict or prohibit all or part of the Services from restricted regions. Please read their applicable User Agreement for more information.
关于 Gate Ventures
Gate Ventures is the venture capital arm of Gate, focusing on investments in decentralized infrastructure, ecosystems, and applications that will reshape the world in the Web 3.0 era. Gate Ventures works with global industry leaders to empower teams and startups with innovative thinking and capabilities to redefine social and financial interaction models.
Official website: https://ventures.gate.io/
Twitter: https://x.com/gate_ventures
Medium: https://medium.com/gate_ventures
This article is sourced from the internet: Gate Ventures Research Insights: The Third Browser War, the Entry Battle in the AI Agent Era
Related: Stablecoin bill passed, FRAX may become the biggest winner?
Original author: Alex Liu, Foresight News Stablecoin Act and FXS On May 20, the US stablecoin legislation bill GENIUS Act passed in the Senate vote. There are still two major steps to go before it is officially passed: the House of Representatives vote and the submission to the President for signature. The market previously believed that the Senate vote was the biggest obstacle to the passage of the bill. If nothing unexpected happens, the complete passage of the bill will only be a matter of time. Which crypto project is the biggest winner of this legislative victory? Judging from the token price performance, it may be Frax Finance. As the bill passed the Senate, Frax Finance token FXS (now renamed FRAX, not yet updated in centralized exchanges) once rose above…







